點我下載:song_rank2.csv
setwd('/Users/carplee/Desktop/IT python')
r = read.csv('data/song_rank2.csv')
r
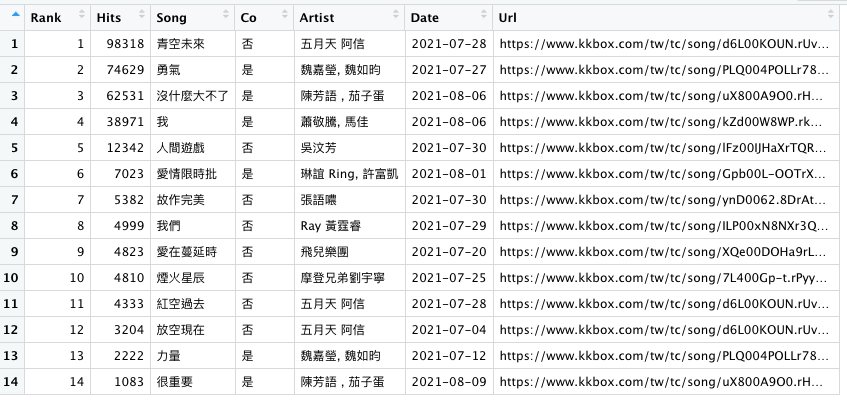
r[1,]
Rank Hits Song Co Artist Date
1 1 98318 青空未來 否 五月天 阿信 2021-07-28
Url
1 https://www.kkbox.com/tw/tc/song/d6L00KOUN.rUv3ePUv3eP0XL-index.html
v=c(1,2)
r[v,] #vector
r[1:2,] #slice
Rank Hits Song Co Artist Date
1 1 98318 青空未來 否 五月天 阿信 2021-07-28
2 2 74629 勇氣 是 魏嘉瑩, 魏如昀 2021-07-27
Url
1 https://www.kkbox.com/tw/tc/song/d6L00KOUN.rUv3ePUv3eP0XL-index.html
2 https://www.kkbox.com/tw/tc/song/PLQ004POLLr78J1P78J1P0XL-index.html
r[,'Artist']
[1] "五月天 阿信" "魏嘉瑩, 魏如昀" "陳芳語 , 茄子蛋"
[4] "蕭敬騰, 馬佳" "吳汶芳 " "琳誼 Ring, 許富凱"
[7] "張語噥 " "Ray 黃霆睿" "飛兒樂團 "
[10] "摩登兄弟劉宇寧" "五月天 阿信" "五月天 阿信"
[13] "魏嘉瑩, 魏如昀" "陳芳語 , 茄子蛋"
r[1:2,'Artist']
[1] "五月天 阿信" "魏嘉瑩, 魏如昀"
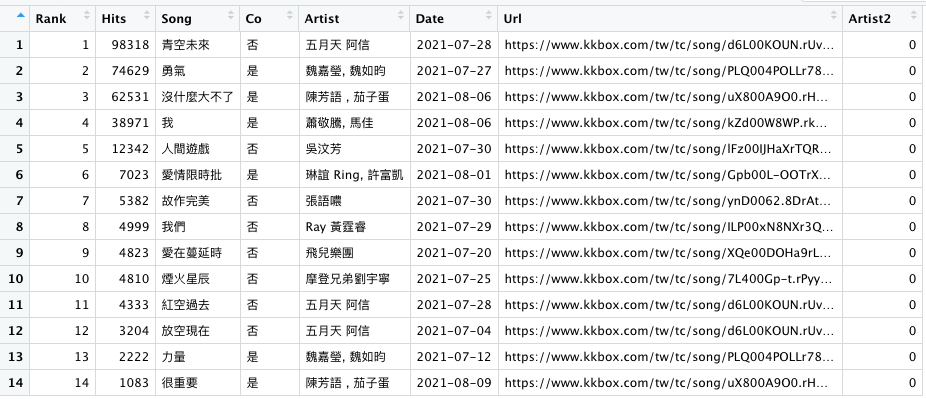
r[, 'Artist2']=0
r
# install.packages('dplyr') # 下載'dplyr'套件
library(dplyr)
library(stringr)
art1 = str_split_fixed(r$Artist, patter=',', 2)[,1] %>% str_trim()
art2 = str_split_fixed(r$Artist, patter=',', 2)[,2] %>% str_trim()
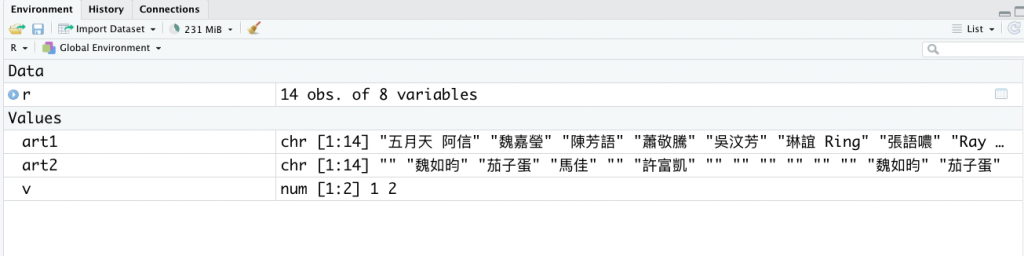
r[, 'art1']=art1
r
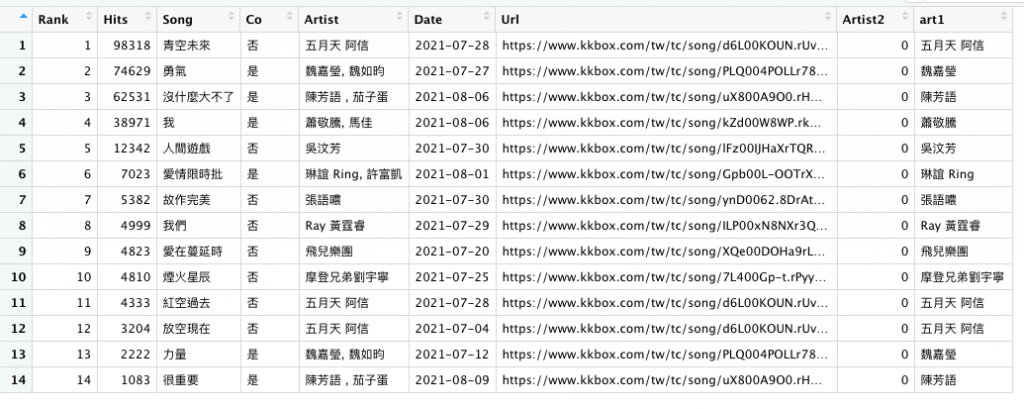
r[, 'art2']=art2
r
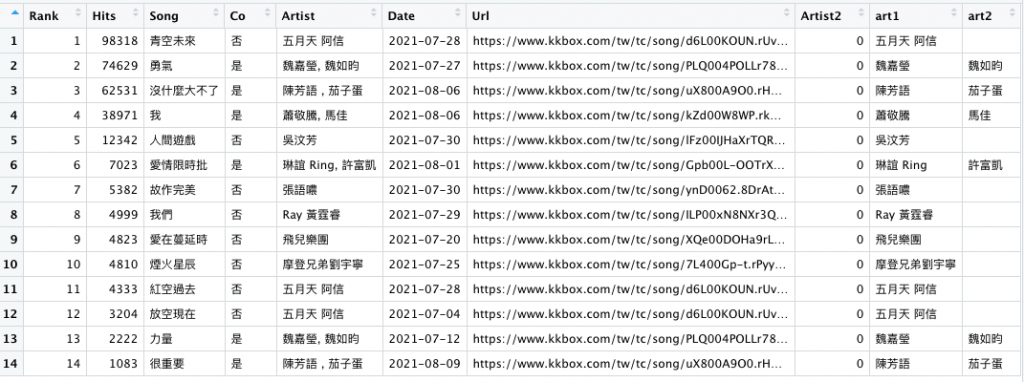
colnames(r)
# [1] "Rank" "Hits" "Song" "Co" "art1" "art2"
# [7] "Artist2" "Date" "Url"
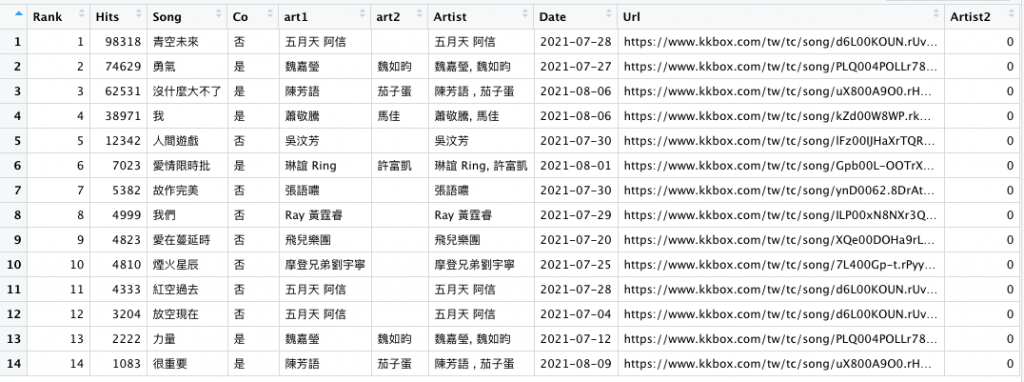
new_l = c("Rank","Hits","Song","Co","art1", "art2", "Artist","Date","Url","Artist2")
r = r[,new_l]
r
write.csv(r, 'data/song_rank3.csv', fileEncoding='utf-8',row.names = FALSE)


 iThome鐵人賽
iThome鐵人賽